
Introduction
Large Language Models (LLMs) exhibit considerable capabilities but encounter obstacles such as hallucination, outdated knowledge, and opaque reasoning processes. Retrieval-Augmented Generation (RAG) emerges as a promising remedy by integrating knowledge from external databases, thereby enhancing model accuracy and credibility, especially for knowledge-intensive tasks. RAG seamlessly combines LLMs’ inherent knowledge with the extensive, ever-changing repositories of external databases.
This comprehensive review paper – Retrieval-augmented generation for large language models: A survey1 thoroughly examines the evolution of RAG paradigms, including Naive RAG, Advanced RAG, and Modular RAG, scrutinizing their tripartite foundation: retrieval, generation, and augmentation techniques. The paper elucidates state-of-the-art technologies within each component, offering a deep understanding of RAG system advancements. Additionally, it introduces metrics and benchmarks for RAG model assessment, along with an updated evaluation framework. Lastly, the paper outlines future research directions, including addressing challenges, expanding into multi-modalities, and advancing RAG infrastructure and its ecosystem.
Advanced Retrieval-Augmented Generation (RAG) represents a refined evolution aimed at rectifying the limitations observed in Naive RAG. This advancement is primarily focused on enhancing retrieval quality through pre-retrieval and post-retrieval strategies. To tackle the indexing challenges inherent in Naive RAG, Advanced RAG employs sophisticated techniques such as sliding window, fine-grained segmentation, and metadata utilization. Moreover, various methods are introduced to optimize the retrieval process.
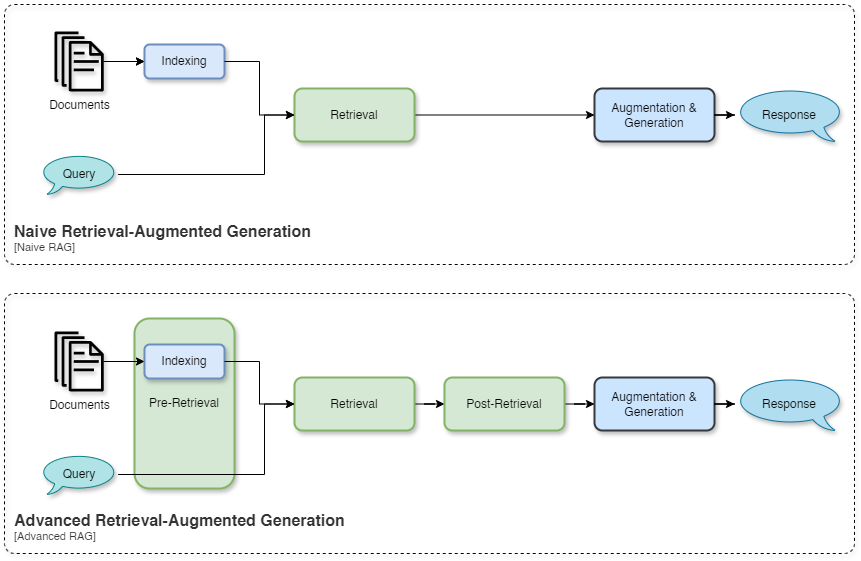
The pre-retrieval process involves several strategies to enhance data indexing quality, including improving data granularity, optimizing index structures, incorporating metadata, aligning content, and employing mixed retrieval. These strategies aim to standardize text, ensure factual accuracy, maintain context, and update outdated information.
During the retrieval stage, emphasis is placed on identifying relevant context by assessing similarity between queries and chunks, with the embedding model playing a central role. Fine-tuning embedding models significantly impacts the relevance of retrieved content, especially in domain-specific contexts. Dynamic embedding, as opposed to static embedding, adapts to contextual nuances, with models like BGE-large-EN showcasing high performance.
In the post-retrieval process, retrieved context is merged with the query input into Large Language Models (LLMs), overcoming context window limitations. Re-ranking strategies are employed to prioritize relevant content, while prompt compression techniques aim to reduce noise and highlight pivotal information. Approaches like Diversity Ranker and LostInTheMiddleRanker focus on reordering based on document diversity and semantic similarity recalculations, respectively. Additionally, methods such as Selective Context and Recomp utilize small language models to estimate element importance and enhance information perception within extensive contexts.
Implementation
We will implement Advanced Retrieval-Augmented Generation (RAG) – Sentence Window Retrieval with MongoDB Atlas and LlamaIndex :
Getting Started
First, setup a new environment in Python/ VSCode. Open a PowerShell terminal within VSCode and use the command ->
python -m venv . venvto create a virtual environment. Activate this virtual environment via the Terminal to your workspace using ->
.venv\Scripts\Activate.ps1Now, install the required libraries using pip->
pip install llama-index
pip install llama-index-vector-stores-mongodb
pip install llama-index-embeddings-openai
pip install pymongo
pip install llama-index-readers-web
pip install sentence-transformers
pip install torch torchvision torchaudio-f https://download.pytorch.org/whl/cu121/torch_stable.htmlCreate an MongoDB Atlas online account if you don’t already have one.
Setup a database in your Atlas Cluster and Index it using Atlas Search.
Navigate to Deployment>Database>Browse Collections->Atlas Search>Actions>Edit Index ->
{
"fields": [
{
"numDimensions": 256,
"path": "embedding",
"similarity": "cosine",
"type": "vector"
}
]
}Code
import time
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.postprocessor import (
MetadataReplacementPostProcessor,
SentenceTransformerRerank,
)
from llama_index.core.settings import Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.vector_stores.mongodb import MongoDBAtlasVectorSearch
from pymongo import MongoClient
# Note: Store the OpenAi API key in the Environment Variables
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# The temperature is used to control the randomness of the output.
# When you set it higher, you'll get more random outputs.
# When you set it lower, towards 0, the values are more deterministic.
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=256)
# MongoDB Atlas Connection Details
mongodb_conn_string = (
"mongodb+srv://<username>:<password>@<cluster>.<server>.mongodb.net/"
)
db_name = "RAGSentenceWindowRetrieval"
collection_name = "SentenceWindow"
index_name = "vector_index"
# Initialize MongoDB python client
mongo_client = MongoClient(mongodb_conn_string)
collection = mongo_client[db_name][collection_name]
# Initialize the MongoDB Atlas Vector Store.
vector_store = MongoDBAtlasVectorSearch(
mongo_client,
db_name=db_name,
collection_name=collection_name,
index_name=index_name,
embedding_key="embedding",
)
def UploadEmbeddingstoAtlas():
# Load the input data into Document list.
documents = SimpleDirectoryReader(input_files=["./input_text.txt"]).load_data(
show_progress=True
)
# Reset w/out deleting the Search Index
collection.delete_many({})
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,#The number of sentences on each side of a sentence to capture.
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_nodes = node_parser.get_nodes_from_documents(documents)
for i in range(0, len(sentence_nodes)):
print("==================")
print(f"Text {str(i+1)}: \n{sentence_nodes[i].text}")
print("------------------")
print(f"Window {str(i+1)}: \n{sentence_nodes[i].metadata['window']}")
print("==================")
print("Initiated Embedding Creation")
print("------------------")
start_time = time.time()
for node in sentence_nodes:
node.embedding = Settings.embed_model.get_text_embedding(
node.get_content(metadata_mode="all")
)
print("Embedding Completed In {:.2f} sec".format(time.time() - start_time))
start_time = time.time()
# Add nodes to MongoDB Atlas Vector Store.
vector_store.add(sentence_nodes)
print(
"Embedding Saved in MongoDB Atlas Vector in {:.2f} sec".format(
time.time() - start_time
)
)
def AskQuestions():
# Retrieve Vector Store Index.
sentence_index = VectorStoreIndex.from_vector_store(vector_store)
# In advanced RAG, the MetadataReplacementPostProcessor is used to replace the sentence in each node
# with it's surrounding context as part of the sentence-window-retrieval method.
# The target key defaults to 'window' to match the node_parser's default
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
# For advanced RAG, add a re-ranker to re-ranks the retrieved context for its relevance to the query.
# Note : Retrieve a larger number of similarity_top_k, which will be reduced to top_n.
# BAAI/bge-reranker-base
# link: https://huggingface.co/BAAI/bge-reranker-base
rerank = SentenceTransformerRerank(top_n=2, model="BAAI/bge-reranker-base")
# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
# Set vector_store_query_mode to "hybrid" to enable hybrid search with an additional alpha parameter
# to control the weighting between semantic and keyword based search.
# The alpha parameter specifies the weighting between vector search and keyword-based search,
# where alpha=0 means keyword-based search and alpha=1 means pure vector search.
query_engine = sentence_index.as_query_engine(
similarity_top_k=6,
vector_store_query_mode="hybrid",
alpha=0.5,
node_postprocessors=[postproc, rerank],
)
# Load the question to ask the RAG into Document list.
question_documents = []
with open(file=".\questions.txt", encoding="ascii") as fIn:
question_documents = set(fIn.readlines())
question_documents = list(question_documents)
# Now, run Advanced RAG queries on your data using the Default RAG queries
for i in range(0, len(question_documents)):
if question_documents[i].strip():
print("==================")
print(f"Question {str(i+1)}: \n{question_documents[i].strip()}")
print("------------------")
response = query_engine.query(question_documents[i].strip())
print(
f"Advanced RAG Response for Question {str(i+1)}: \n{str(response).strip()}"
)
time.sleep(20)
print("------------------")
if(str(response).strip()!='Empty Response'):
window = response.source_nodes[0].node.metadata["window"]
sentence = response.source_nodes[0].node.metadata["original_text"]
print(f"Referenced Window for Question {str(i+1)}:\n {window}")
print("------------------")
print(f"Original Response Sentence for Question {str(i+1)}: \n{sentence}")
print("==================")
#Only required to run once for creating and storing the embedding to the MongoDB Atlas Cloud
UploadEmbeddingstoAtlas()
#Run the retrieve Advanced RAG queries responses for queries in question.txt file
AskQuestions()Output
PS C:\Code\Python\Environment\AdvancedRAGWithMongoDB> c:\Code\Python\Environment\AdvancedRAGWithMongoDB\.venv\Scripts\Activate.ps1
(.venv) PS C:\Code\Python\Environment\AdvancedRAGWithMongoDB> python .\RAGSentenceWindowRetrievalMongoDB.py
Loading files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 9.91file/s]
==================
Text 1:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors.
------------------
Window 1:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Text 2:
This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
------------------
Window 2:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations.
==================
==================
Text 3:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
------------------
Window 3:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
==================
==================
Text 4:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
------------------
Window 4:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
==================
==================
Text 5:
Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations.
------------------
Window 5:
This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
==================
==================
Text 6:
Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Window 6:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
==================
Initiated Embedding Creation
------------------
Embedding Completed In 67.14 sec
Embedding Saved in MongoDB Atlas Vector in 0.26 sec
==================
Question 1:
What types of vectors does Faiss specialize in handling?
------------------
Advanced RAG Response for Question 1:
Faiss specializes in handling dense vectors, particularly those encountered in high-dimensional machine learning applications like image recognition and recommendation systems.
------------------
Referenced Window for Question 1:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 1:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
==================
==================
Question 2:
Where can real-world application scenarios of Faiss be found?
------------------
Advanced RAG Response for Question 2:
The real-world application scenarios of Faiss can be found outlined in the Facebook Engineering blog post.
------------------
Referenced Window for Question 2:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 2:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
==================
==================
Question 3:
Who developed Faiss?
------------------
Advanced RAG Response for Question 3:
Facebook developed Faiss.
------------------
Referenced Window for Question 3:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 3:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 4:
What hardware configurations does Faiss support?
------------------
Advanced RAG Response for Question 4:
Faiss supports both CPU and GPU implementations, ensuring scalability across different hardware configurations.
------------------
Referenced Window for Question 4:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 4:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 5:
What techniques does Faiss use to accelerate similarity searches?
------------------
Advanced RAG Response for Question 5:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches.
------------------
Referenced Window for Question 5:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 5:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 6:
What is the purpose of Faiss?
------------------
Advanced RAG Response for Question 6:
The purpose of Faiss is to provide an open-source library developed by Facebook for efficient similarity searches and clustering of dense vectors in machine learning applications, particularly those involving high-dimensional vectors like image recognition and recommendation systems. It offers features like scalability, flexibility, and support for both CPU and GPU implementations, allowing users to conduct both exact and approximate similarity searches based on their specific requirements.
------------------
Referenced Window for Question 6:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 6:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
==================
==================
Question 7:
What challenges does Faiss address in machine learning applications?
------------------
Advanced RAG Response for Question 7:
Faiss addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
------------------
Referenced Window for Question 7:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations.
------------------
Original Response Sentence for Question 7:
This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
==================
==================
Question 8:
How does Faiss support scalability in large datasets?
------------------
Advanced RAG Response for Question 8:
Faiss supports scalability in large datasets by offering support for both CPU and GPU implementations.
------------------
Referenced Window for Question 8:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 8:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 9:
What options does Faiss offer for similarity searches?
------------------
Advanced RAG Response for Question 9:
Faiss offers options for both exact and approximate similarity searches.
------------------
Referenced Window for Question 9:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 9:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 10:
What features make Faiss valuable for machine learning and data analysis tasks?
------------------
Advanced RAG Response for Question 10:
Faiss is valuable for machine learning and data analysis tasks due to its widespread applicability, scalability, and flexibility. It offers support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Additionally, Faiss provides options for both exact and approximate similarity searches, allowing users to customize the level of precision according to their specific requirements.
------------------
Referenced Window for Question 10:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 10:
Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
==================
==================
Question 11:
How can users adjust the precision level in Faiss?
------------------
Advanced RAG Response for Question 11:
Users can adjust the precision level in Faiss by choosing between options for both exact and approximate similarity searches, allowing them to tailor the level of precision to their specific requirements.
------------------
Referenced Window for Question 11:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 11:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 12:
What are some examples of real-world application scenarios of Faiss outlined in the Facebook Engineering blog post?
------------------
Advanced RAG Response for Question 12:
Real-world application scenarios of Faiss outlined in the Facebook Engineering blog post include image recognition and recommendation systems.
------------------
Referenced Window for Question 12:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations.
------------------
Original Response Sentence for Question 12:
This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
==================
==================
Question 13:
What is Faiss?
------------------
Advanced RAG Response for Question 13:
Faiss is an open-source library developed by Facebook for efficient similarity searches and clustering of dense vectors. It addresses challenges commonly encountered in machine learning applications involving high-dimensional vectors, such as image recognition and recommendation systems. Faiss offers features like scalability, flexibility, and support for both CPU and GPU implementations, making it a valuable tool for various machine learning and data analysis tasks.
------------------
Referenced Window for Question 13:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 13:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
==================
Question 14:
In what types of systems is Faiss commonly used?
------------------
Advanced RAG Response for Question 14:
Faiss is commonly used in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
------------------
Referenced Window for Question 14:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations.
------------------
Original Response Sentence for Question 14:
This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems.
==================
==================
Question 15:
How does Faiss contribute to image recognition?
------------------
Advanced RAG Response for Question 15:
Faiss contributes to image recognition by providing efficient similarity searches and clustering of dense vectors. It addresses challenges commonly encountered in machine learning applications involving high-dimensional vectors, which are essential in tasks like image recognition. Faiss's advanced techniques like indexing and quantization accelerate similarity searches in large datasets, making it a valuable tool for image recognition systems.
------------------
Referenced Window for Question 15:
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post.
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements.
------------------
Original Response Sentence for Question 15:
Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets.
==================
(.venv) PS C:\Code\Python\Environment\AdvancedRAGWithMongoDB> Outputs Comparison
| Semantic Search on FAISS | Semantic Search using LangChain and MongoDB Atlas And Contextual Compression | Advanced Retrieval-Augmented Generation (RAG) with MongoDB Atlas and LlamaIndex : Sentence Window Retrieval and Embedding model “text-embedding-3-small” with 256 dimensions | Advanced Retrieval-Augmented Generation (RAG) with MongoDB Atlas and LlamaIndex : Sentence Window Retrieval and Embedding model “sentence-transformers/all-mpnet-base-v2” with 768 dimensions |
|---|---|---|---|
| Query: What is FAISS? | Query: What is FAISS? | Query: What is FAISS? | Query: What is FAISS? |
| Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post. Faiss employs advanced techniques like indexing and quantization to accelerate similarity searches in large datasets. Its versatility is evident in its support for both CPU and GPU implementations, ensuring scalability across different hardware configurations. Faiss offers flexibility with options for both exact and approximate similarity searches, allowing users to tailor the level of precision to their specific requirements. |
Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook, designed for efficient similarity searches and clustering of dense vectors. This library addresses challenges commonly encountered in machine learning applications, particularly those involving high-dimensional vectors, such as image recognition and recommendation systems. Its widespread applicability, combined with features like scalability and flexibility, makes it a valuable tool for various machine learning and data analysis tasks, as demonstrated in its real-world application scenarios outlined in the Facebook Engineering blog post. | Faiss is an open-source library developed by Facebook for efficient similarity searches and clustering of dense vectors. It addresses challenges commonly encountered in machine learning applications involving high-dimensional vectors, such as image recognition and recommendation systems. Faiss offers features like scalability, flexibility, and support for both CPU and GPU implementations, making it a valuable tool for various machine learning and data analysis tasks. | Faiss is an open-source library developed by Facebook for efficient similarity searches and clustering of dense vectors. It addresses challenges in machine learning applications involving high-dimensional vectors like image recognition and recommendation systems. Faiss offers features like scalability, flexibility, and supports both CPU and GPU implementations for scalability across different hardware configurations. It provides options for both exact and approximate similarity searches to allow users to adjust precision based on their requirements. |
GitHub: https://github.com/mohammaddaoudfarooqi/AdvancedRAGWithMongoDB
Conclusion
This article discussed the concept of Advanced Retrieval-Augmented Generation (RAG), which encompasses a range of techniques aimed at overcoming the limitations of the naive RAG approach. Following an examination of advanced RAG methodologies, which can be segmented into pre-retrieval, retrieval, and post-retrieval techniques, the article proceeded to construct and execute both naive and advanced RAG pipelines utilizing LlamaIndex for coordination.
The components of the RAG pipeline included language models sourced from OpenAI, a Re-Ranker model provided by BAAI/bge-reranker-base on Hugging Face, and MongoDB Atlas Vector database.
In Python, we implemented the following array of techniques utilizing LlamaIndex:
- Pre-retrieval optimization: Employing sentence window retrieval
- Retrieval optimization: Utilizing hybrid search techniques
- Post-retrieval optimization: Implementing re-ranking strategies
References
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., … & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997. ↩︎
- https://towardsdatascience.com/advanced-retrieval-augmented-generation-from-theory-to-llamaindex-implementation-4de1464a9930
- https://towardsdatascience.com/advanced-rag-01-small-to-big-retrieval-172181b396d4
- https://docs.llamaindex.ai/en/latest/examples/node_postprocessor/MetadataReplacementDemo.html
- https://docs.llamaindex.ai/en/stable/examples/retrievers/recursive_retriever_nodes.html
- https://docs.haystack.deepset.ai/docs/hypothetical-document-embeddings-hyde
- https://www.mongodb.com/developer/products/atlas/rag-with-polm-stack-llamaindex-openai-mongodb/
- https://docs.llamaindex.ai/en/stable/api/llama_index.core.node_parser.SentenceWindowNodeParser.html
- https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo.html


