
In this blog post, we’ll explore the implementation of an ArXiv Research Assistant using LangGraph, MongoDB, and AWS Bedrock. This application allows users to search and summarize academic papers from arXiv using a combination of full-text and vector-based search techniques. We’ll dive into the key components of the system and explain how they work together to provide a powerful research tool.
System Overview
The ArXiv Research Assistant is built with the following key components:
- MongoDB for document storage and retrieval
- AWS Bedrock for embeddings and language model inference
- LangGraph for workflow orchestration
- Gradio for the user interface
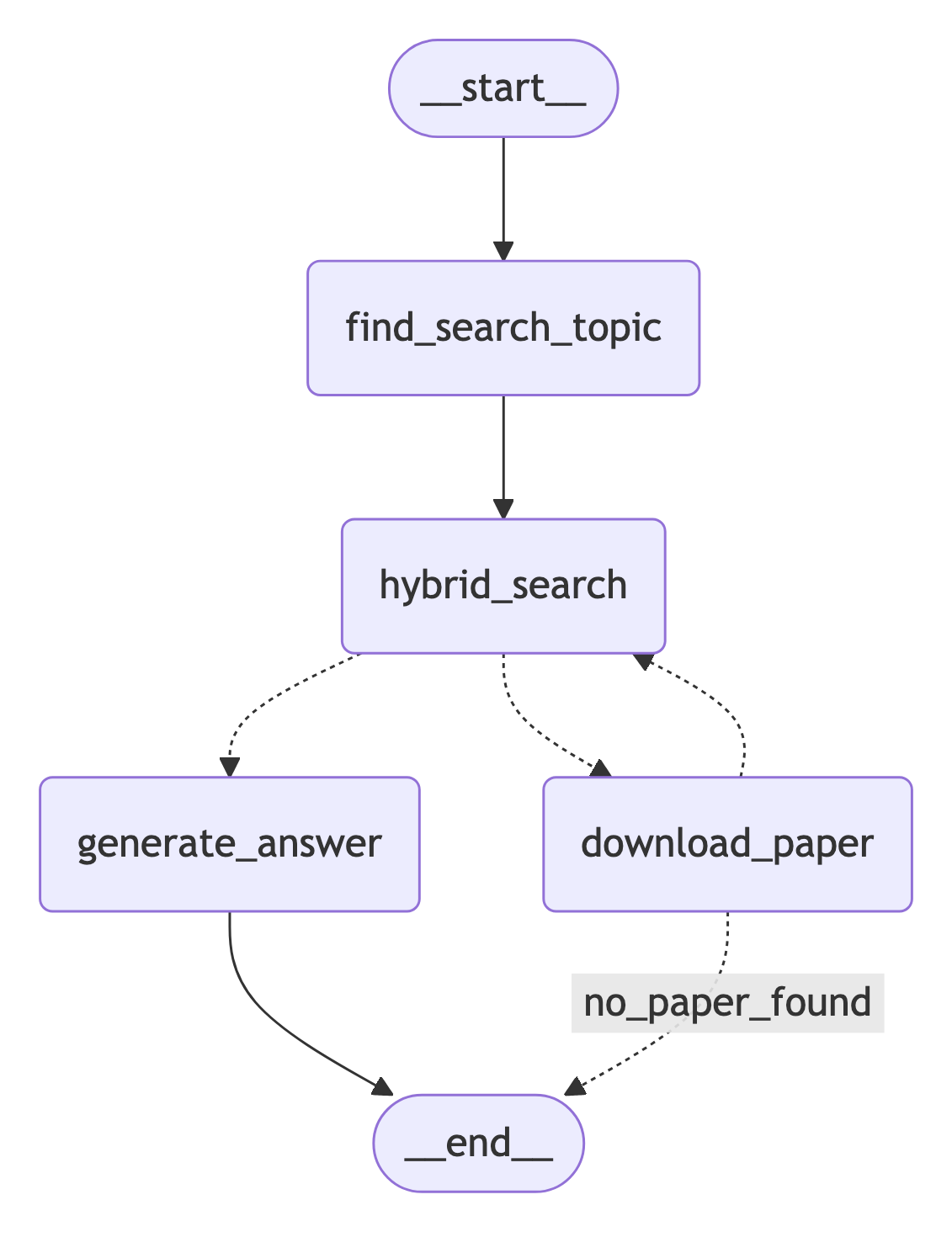
The system follows these main steps:
- Accept a user query
- Identify the core search topic
- Perform a hybrid search (full-text + vector) on stored documents
- Download and process new papers if necessary
- Generate a comprehensive answer based on the retrieved documents
Let’s explore each component in detail.
MongoDB Setup and Indexing
We use MongoDB to store and retrieve academic papers. The system sets up two crucial indexes:
- A vector search index for efficient similarity searches
- A full-text search index for keyword-based searches
def setup_vector_search_index():
index_definitions = [
{
"name": VECTOR_SEARCH_INDEX_NAME,
"type": "vectorSearch",
"definition": {
"fields": [
{
"type": "vector",
"path": "embeddings",
"numDimensions": 1536,
"similarity": "cosine",
}
]
},
},
{
"name": SEARCH_INDEX_NAME,
"type": "search",
"definition": {
"mappings": {
"dynamic": False,
"fields": {"text": {"type": "string"}},
}
},
},
]
for index_definition in index_definitions:
try:
collection.create_search_index(model=index_definition)
time.sleep(10)
except pymongo.errors.PyMongoError:
passThis function ensures that our MongoDB collection has the necessary indexes for efficient searching.
Hybrid Search Implementation
The hybrid search combines full-text search and vector-based search to provide more accurate and relevant results:
def hybrid_search(query, vector_query, weight=0.5, top_n=10):
"""
Perform hybrid search with semantic boosting on MongoDB.
:param query: The full-text search query
:param vector_query: The vector search query
:param weight: Weight for semantic (vector) score (0-1)
:param top_n: Limit for top N results in vector search
:return: Aggregation pipeline results
"""
# Ensure weight is between 0 and 1
assert 0 <= weight <= 1, "Weight must be between 0 and 1"
pipeline = [
{
"$search": {
"index": "full_text_index",
"text": {"query": query, "path": "text"},
}
},
{"$addFields": {"fts_score": {"$meta": "searchScore"}}},
{"$setWindowFields": {"output": {"maxScore": {"$max": "$fts_score"}}}},
{
"$addFields": {
"normalized_fts_score": {"$divide": ["$fts_score", "$maxScore"]}
}
},
{"$project": {"text": 1, "normalized_fts_score": 1}},
{
"$unionWith": {
"coll": collection.name,
"pipeline": [
{
"$vectorSearch": {
"index": VECTOR_SEARCH_INDEX_NAME,
"queryVector": vector_query, # Parameterized vector query
"path": "embeddings",
"numCandidates": 200,
"limit": top_n, # Limit for vector search results
}
},
{"$addFields": {"vs_score": {"$meta": "vectorSearchScore"}}},
{
"$setWindowFields": {
"output": {"maxScore": {"$max": "$vs_score"}}
}
},
{
"$addFields": {
"normalized_vs_score": {
"$divide": ["$vs_score", "$maxScore"]
}
}
},
{"$project": {"text": 1, "normalized_vs_score": 1}},
],
}
},
{
"$group": {
"_id": "$_id", # Replace with the unique identifier field
"fts_score": {"$max": "$normalized_fts_score"},
"vs_score": {"$max": "$normalized_vs_score"},
"text_field": {"$first": "$text"},
}
},
{
"$addFields": {
"hybrid_score": {
"$add": [
{"$multiply": [weight, {"$ifNull": ["$vs_score", 0]}]},
{"$multiply": [1 - weight, {"$ifNull": ["$fts_score", 0]}]},
]
}
}
},
{"$sort": {"hybrid_score": -1}},
{
"$limit": top_n # Limit for final hybrid results
},
{
"$project": {
"_id": 0, # Exclude the ID field from the output
"fts_score": 1,
"vs_score": 1,
"score": "$hybrid_score",
"text": "$text_field",
}
},
]
# Execute the pipeline
results = list(collection.aggregate(pipeline))
return resultsThis function uses MongoDB’s aggregation pipeline to perform a weighted combination of full-text and vector searches, providing a flexible and powerful search mechanism.
ArXiv Integration
The system integrates with ArXiv to fetch and download papers based on user queries:
def fetch_arxiv_papers(query: str, max_results: int = 5) -> List[Dict]:
"""
Fetches papers from arXiv based on a search query.
Args:
query (str): The search query string.
max_results (int, optional): The maximum number of results to return. Defaults to 5.
Returns:
List[Dict]: A list of dictionaries, each containing details of a paper:
- title (str): The title of the paper.
- authors (List[str]): A list of author names.
- summary (str): The summary of the paper.
- published (str): The publication date in ISO format.
- pdf_url (str): The URL to the PDF of the paper.
- arxiv_url (str): The URL to the paper's arXiv entry.
"""
print("fetch_arxiv_papers", query)
query = urllib.parse.quote(f"all:{query}")
search = arxiv.Search(
query=query,
max_results=max_results,
sort_by=arxiv.SortCriterion.Relevance,
sort_order=arxiv.SortOrder.Descending,
)
# Use the Client for searching
client = arxiv.Client()
# Execute the search
searchResults = client.results(search)
return [
{
"title": paper.title,
"authors": [author.name for author in paper.authors],
"summary": paper.summary,
"published": paper.published.isoformat(),
"pdf_url": paper.pdf_url,
"arxiv_url": paper.entry_id,
}
for paper in searchResults
]This function uses the arxiv library to search for and retrieve paper metadata from ArXiv.
AWS Bedrock Integration
AWS Bedrock is used for generating embeddings and performing language model inference:
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1", config=config)
embedding_model = BedrockEmbeddings(
model_id=EMBEDDING_MODEL_NAME, client=bedrock_client
)The BedrockEmbeddings class is used to generate embeddings for documents and queries, while the bedrock_client is used for language model inference in functions like find_search_topic and generate_answer.
LangGraph Workflow
The core of the application is built using LangGraph, which orchestrates the workflow:
workflow = StateGraph(GraphState)
def create_graph_nodes():
"""
Creates and configures the nodes and edges for the workflow graph.
This function sets up the workflow by adding nodes and defining the
relationships between them through edges and conditional edges. The
workflow consists of the following nodes:
- "find_search_topic": Identifies the search topic.
- "hybrid_search": Performs a hybrid search.
- "download_paper": Downloads the papers.
- "generate_answer": Generates the answer.
The edges and conditional edges define the flow of the workflow:
- START -> "find_search_topic"
- "find_search_topic" -> "hybrid_search"
- Conditional edges from "hybrid_search" based on `check_documents_extracted`:
- "download_paper" if documents are extracted.
- "generate_answer" if no documents are extracted.
- Conditional edges from "download_paper" based on `check_downloaded_papers`:
- "hybrid_search" if papers are downloaded.
- "no_paper_found" (END) if no papers are found.
- "generate_answer" -> END
"""
workflow.add_node("find_search_topic", find_search_topic)
workflow.add_node("hybrid_search", perform_hybrid_search)
workflow.add_node("download_paper", download_papers)
workflow.add_node("generate_answer", generate_answer)
workflow.add_edge(START, "find_search_topic")
workflow.add_edge("find_search_topic", "hybrid_search")
workflow.add_conditional_edges(
"hybrid_search",
check_documents_extracted,
{"download_paper": "download_paper", "generate_answer": "generate_answer"},
)
workflow.add_conditional_edges(
"download_paper",
check_downloaded_papers,
{"hybrid_search": "hybrid_search", "no_paper_found": END},
)
workflow.add_edge("generate_answer", END)
setup_vector_search_index()
create_graph_nodes()
app = workflow.compile()This setup defines the workflow as a graph, with nodes representing different stages of the process and edges defining the flow between these stages.
Gradio User Interface
The user interface is implemented using Gradio, providing a chat-like interface for interacting with the ArXiv Research Assistant:
with gr.Blocks(
fill_height=True,
fill_width=True,
title="ArXiv Research Assistant",
theme=gr.themes.Soft(),
) as demo:
gr.ChatInterface(
fn=handle_query,
type="messages",
title="ArXiv Research Assistant",
description="<center>Get assistance in searching and summarizing academic papers from arXiv.</center>",
multimodal=False,
fill_height=True,
fill_width=False,
show_progress=False,
concurrency_limit=None,
# ... (other configuration options)
)The handle_query function processes user inputs and streams the results back to the interface.
Applications of an arXiv Research Assistant Powered by RAG
A Retrieval-Augmented Generation (RAG) model applied to the arXiv repository could serve as a transformative tool for efficiently extracting and synthesizing insights from the extensive collection of scientific papers. Here are some potential use cases that highlight its versatility and value:
1. Scientific Literature Review
- Researchers can query the RAG system with specific questions or topics, such as “What are the latest advancements in quantum computing?” or “How does reinforcement learning apply to robotics?”
- The system retrieves relevant papers from arXiv, extracts key findings, and generates a coherent summary or explanation, streamlining the literature review process.
2. Automated Research Assistance
- Assists researchers in identifying gaps in the literature, emerging trends, or summarizing methodologies from multiple sources.
- Answers highly specific technical questions by synthesizing information across papers, saving significant time and effort.
3. Educational Applications
- Students and educators can use the system to demystify complex scientific concepts or provide concise overviews of research areas.
- It can generate study guides, FAQs, or detailed explanations of technical topics tailored to a specific audience.
4. Fostering Cross-disciplinary Collaboration
- Enables researchers from diverse fields to comprehend papers outside their expertise, fostering interdisciplinary innovation.
- For instance, a biologist exploring machine learning applications in genomics can gain accessible summaries of relevant computer science research.
5. Support for Patent and Grant Proposals
- Inventors and grant writers can identify prior work and gather relevant references, ensuring their proposals are novel and well-informed.
- The system can help generate theoretical frameworks and summaries to strengthen application narratives.
6. Staying Updated with Recent Advances
- Delivers personalized summaries of newly published arXiv papers on a daily or weekly basis, tailored to individual research interests.
- Ensures researchers remain current without having to sift through extensive lists of new publications.
7. Contextual Code Retrieval and Explanation
- For papers containing code snippets or pseudo-code, the system can extract and provide detailed explanations or runnable examples, enhancing reproducibility and accelerating practical applications.
By integrating RAG with arXiv, this system has the potential to revolutionize how knowledge is consumed and utilized across academia, industry, and beyond. Researchers, students, and professionals alike would benefit from its ability to make cutting-edge science more accessible, comprehensible, and actionable.
Conclusion
The ArXiv Research Assistant demonstrates the power of combining modern AI technologies with efficient data storage and retrieval systems. By leveraging LangGraph for workflow orchestration, MongoDB Atlas for flexible document storage and searching, and AWS Bedrock for state-of-the-art language models, we’ve created a powerful tool for helping with academic research.
This system showcases several key concepts:
- Hybrid search techniques combining full-text and vector-based approaches
- Integration of external APIs (ArXiv) for real-time data retrieval
- Use of large language models for topic extraction and answer generation
- Graph-based workflow management for complex AI applications
- Building user-friendly interfaces for AI-powered tools
Future improvements could include adding more sources beyond ArXiv, implementing user feedback mechanisms, and exploring more advanced retrieval and summarization techniques.
GitHub: https://github.com/mohammaddaoudfarooqi/arXivSearch


