
Introduction to Databases:
Databases are structured collections of data organized for efficient storage, retrieval, and manipulation. They are integral to various software applications, ranging from simple web apps to complex enterprise systems. Understanding different database types is essential for selecting the most suitable solution for specific use cases.
Here’s a brief overview of some common types of databases:
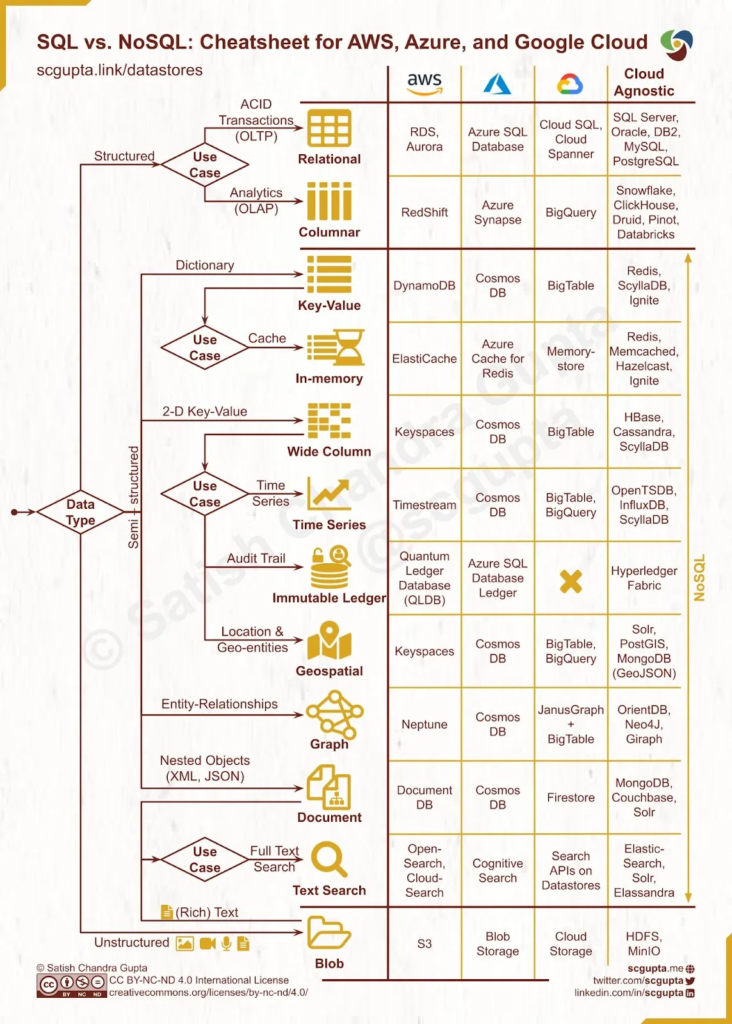
1. Relational Databases (RDBMS):
Overview: Relational databases store data in structured tables with rows and columns, adhering to predefined schemas. They utilize SQL (Structured Query Language) for data manipulation and querying.
Characteristics:
- Structured data model with relationships defined by foreign keys.
- ACID (Atomicity, Consistency, Isolation, Durability) properties ensure data integrity.
- Support for complex queries and transactions.
- Well-established, mature technology with robust security features.
- Normalization techniques minimize redundancy and maintain data consistency.
Examples:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
Use Cases: Relational databases are suitable for applications with structured data and complex relationships, such as financial systems, CRM (Customer Relationship Management) software, and inventory management systems.
Advantages:
- Data integrity through ACID compliance.
- Strong support for complex queries and transactions.
- Mature ecosystem with extensive tooling and resources.
- Well-suited for applications with well-defined schemas.
Disadvantages:
- Limited scalability compared to NoSQL databases.
- Performance degradation with complex joins and large datasets.
- Not ideal for handling unstructured or semi-structured data.
2. NoSQL Databases:
Overview: NoSQL databases offer a flexible approach to data storage, accommodating diverse data types and scalability requirements. They diverge from the rigid structure of relational databases, allowing for schema-less or semi-structured data.
Types:
- Document Stores
- Key-Value Stores
- Column-Family Stores
- Graph Databases
Characteristics:
- Flexible schema or schema-less design.
- Horizontal scalability with distributed architectures.
- Optimized for performance and scalability.
- Support for eventual consistency and partition tolerance.
- Suited for handling unstructured or semi-structured data.
Examples:
- MongoDB (Document Store)
- Redis (Key-Value Store)
- Cassandra (Column-Family Store)
- Neo4j (Graph Database)
Use Cases: NoSQL databases are suitable for applications with dynamic schemas, high scalability requirements, and diverse data formats, such as social media platforms, IoT devices, and real-time analytics.
Advantages:
- Scalability and performance for large datasets and high throughput.
- Flexible data modeling to accommodate evolving requirements.
- Suitable for unstructured or semi-structured data.
- Distributed architectures support fault tolerance and high availability.
Disadvantages:
- Eventual consistency may lead to data inconsistency in distributed systems.
- Lack of standardized querying language compared to SQL.
- Data modeling complexity can increase with denormalization.
3. NewSQL Databases:
Overview: NewSQL databases combine the benefits of traditional SQL databases with the scalability and performance of NoSQL solutions. They provide ACID compliance and strong consistency while supporting distributed architectures.
Examples:
- Google Spanner
- CockroachDB
Characteristics:
- ACID compliance and strong consistency.
- Distributed architectures for scalability and fault tolerance.
- Support for SQL queries and transactions.
- Horizontal scalability without sacrificing consistency.
Use Cases: NewSQL databases are suitable for applications requiring both scalability and ACID compliance, such as online transaction processing (OLTP) systems and distributed databases.
Advantages:
- ACID compliance ensures data integrity and consistency.
- Scalability without sacrificing strong consistency.
- Support for SQL queries and transactions.
- Suitable for mission-critical applications requiring high reliability.
Disadvantages:
- Limited adoption and ecosystem compared to traditional SQL and NoSQL databases.
- Higher complexity in deployment and configuration.
- Performance may not match specialized NoSQL solutions for certain use cases.
4. In-Memory Databases:
Overview: In-memory databases primarily store data in RAM, offering extremely fast data access compared to disk-based storage. They are commonly used for caching and real-time data processing.
Examples:
- Redis
- Memcached
- VoltDB
Characteristics:
- Data stored in memory for ultra-fast access.
- High throughput and low latency.
- Suitable for caching frequently accessed data.
- Optimized for real-time analytics and high-speed transactions.
Use Cases: In-memory databases are ideal for applications where low-latency data access is critical, such as caching in web applications, real-time analytics, and high-frequency trading systems.
Advantages:
- Exceptional performance with low-latency data access.
- Ideal for caching frequently accessed data.
- Well-suited for real-time analytics and high-speed transactions.
Disadvantages:
- Limited by available memory capacity.
- Data durability may be a concern in case of system failure.
- Higher cost per unit of memory compared to disk-based storage.
5. Time-Series Databases:
Overview: Time-series databases specialize in storing and analyzing time-stamped data, such as sensor readings, financial market data, and application metrics. They optimize data storage and retrieval for time-based queries.
Examples:
- InfluxDB
- Prometheus
- TimescaleDB
Characteristics:
- Optimized for storing and querying time-series data.
- Efficient storage and retrieval of timestamped data points.
- Support for aggregations, downsampling, and real-time analytics.
- Scalable architectures for handling high-volume time-series data.
Use Cases: Time-series databases are suitable for applications requiring storage and analysis of time-stamped data, such as IoT sensor data monitoring, financial market data analysis, and infrastructure and application performance monitoring.
Advantages:
- Optimized for efficient storage and retrieval of time-series data.
- Support for real-time analytics and monitoring.
- Scalable architectures for handling high-volume data streams.
Disadvantages:
- May lack support for general-purpose querying beyond time-based operations.
- Specialized use case limits applicability to time-series data.
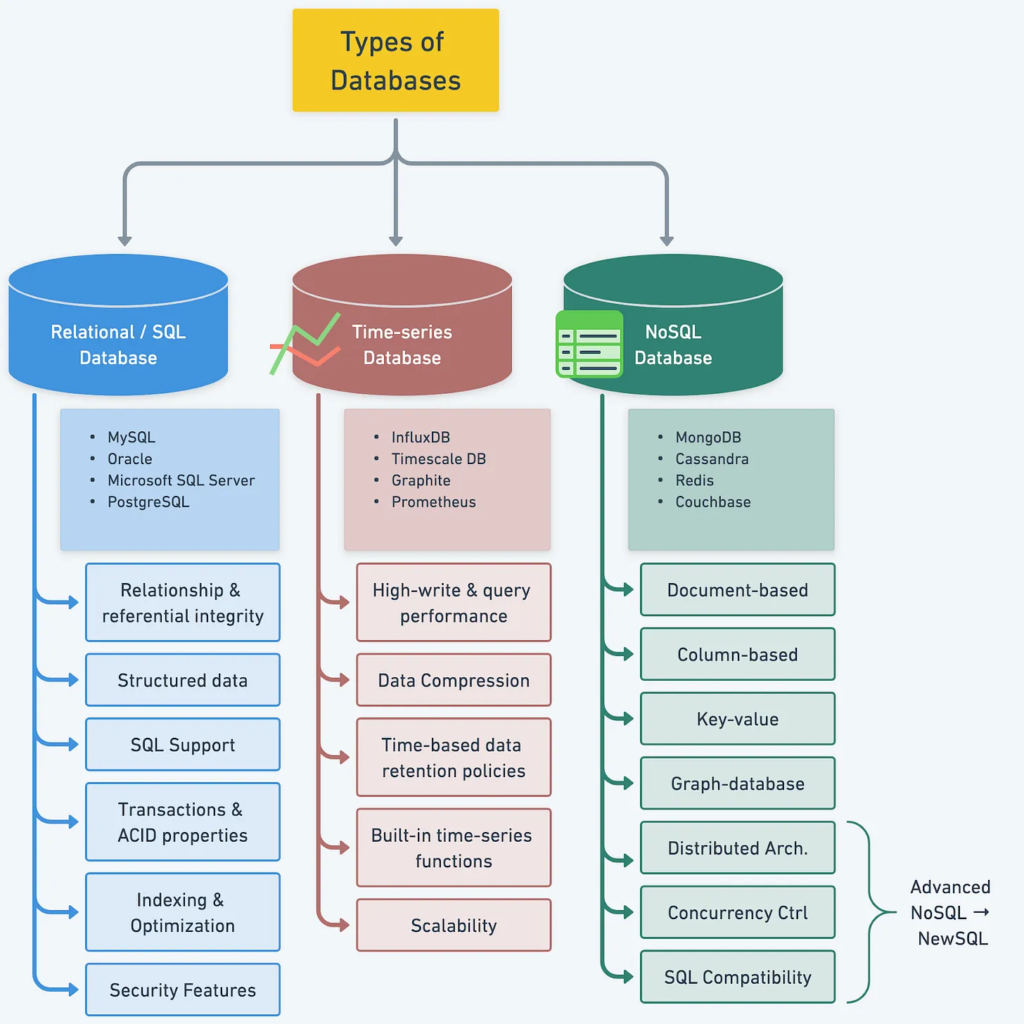
Conclusion:
Each type of database offers unique advantages and is suitable for specific use cases.
- Relational databases excel in structured data storage and complex queries, while NoSQL databases provide flexibility and scalability for diverse data formats.
- NewSQL databases bridge the gap between SQL and NoSQL paradigms, offering ACID compliance with scalability.
- In-memory databases optimize performance with fast data access, and time-series databases specialize in efficient storage and analysis of time-stamped data.
- By understanding the characteristics, use cases, advantages, and disadvantages of each database type, organizations can make informed decisions to meet their data storage and processing requirements effectively.


